
We’ve got a new home: Visit us here: https://analyticsdefined.com/
Deep learning and natural language processing (NLP) have been dominating the pattern recognition in the last few years. To add to the complexity, voice recognition has also joined the race.
This post is an attempt to explain one of the most exciting topics in deep learning, word embedding.
Word Embedding
In layman terms, word embedding is a technique used in Deep learning to turn words into numbers so that they can be processed by many of the machine learning algorithms which normally cannot work on strings of plain text.
The word embedding is a parameterized function: W : words → Rn which is used for mapping words in some language to high dimensional-vectors.
The function is basically a look-up table which is parameterized by a matrix θ in which there exists a row for each of the word: Wθ (wn) = θn.
W is initialized to have some random vectors for each word and it gradually learns to have meaningful vectors in order to perform any task. For example:
- The task can be to train the network to tell whether a 5-gram (sequence of 5 words) is valid or not.
- The training data for this task will be: legal 5-grams, example, “cat sat on the mat”.
We can now break half of them by switching them with a random word which will make the 5-gram nonsensical, e.g.: “cat sat song the mat“.
Network for determining valid 5-gram
The model will now run each of the words in the 5-gram through W to get the vector that represents each of the word in the 5-gram. These are then fed to another module “R” which tries to predict if the 5-gram is broken or valid.
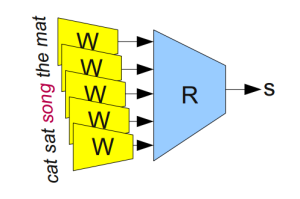
The output:
R(W(“cat”), W(“sat”), W(“on”), W(“the”), W(“mat”)) = 1
R(W(“cat”), W(“sat”), W(“on”), W(“the”), W(“mat”)) = 0
For the model to be accurate, the network needs to learn good parameters for both W and R. R in the model is not as interesting, the point is to learn the parameters for W.
Visualizing Word embedding
To get a feel of word embedding, we can visualise them with t-SNE which is a sophisticated technique used for visualizing high-dimensional data.

The above visualization is intuitive where words with similar meanings are closer to each other.
Power of word embeddings
This is how networks try to make words with similar meanings have same vectors. This helps in determining which words are closest in embedding to the given word which helps in generalizing from one sentence to class of similar sentences. For e.g.:
“the car is black” → “the car is white”
“the car is black” → “the vehicle is white”
As the number of words in a sentence, the impact of this increases exponentially.
Word embedding and analogies
Analogies help the network in generalizing new combinations of words. Analogies between the words are encoded in difference vectors between the words.
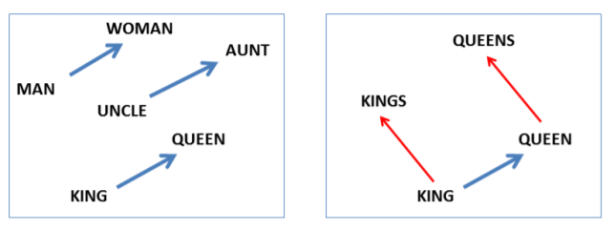
For e.g.:
W(woman) – W(man) ≈ W(aunt) – W(uncle)
W(woman) – W(man) ≈W(queen) – W(king)
This may not be surprising as gender pronouns mean that switching the word can make a sentence grammatically incorrect. We write, “she is the aunt” and “he is the uncle”, similarly “he is the king” and “she is the queen”. A sentence like, “she is the uncle” is most likely a grammatical error. Randomly switching the words in the sentence is most likely to cause this. For this, there is a gender dimension, the way we have one for singular/plural which makes it easy to find these trivial relationships. There are much more sophisticated relationships which are also encoded the same way!
Some helpful links to understand word embedding better:
- Recurrent Neural Networks with Word Embeddings
- http://p.migdal.pl/2017/01/06/king-man-woman-queen-why.html
- https://ronxin.github.io/wevi/
- What is word embedding in deep learning?
- Deep Learning, NLP, and Representations
References:
- Bottou, L´eon(2011). “From Machine Learning to Machine Reasoning” : Machine Learning, p. 2-5
- Collobart Ronan, Weston Jason, Bottou L´eon, Karlen Micheal, Koray Kavukcuoglu, Pavel Kuksa (2011): “Natural Language Processing (almost) from Scratch”: arXiv, p. 23
- Turian Joseph, Ratinov Lev and Bengio Yoshua (2010): “Word representations:
A simple and general method for semi-supervised learning” : ACL ’10 Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics - Tomas Mikolov, Wen-tau Yih, Geoffrey Zweig (2013): “Linguistic Regularities in Continuous Space Word Representations”: Microsoft Research, p. 2-3

Quite simple and to the point article. Thanks Abhay.
LikeLiked by 1 person
Thanks! 🙂
LikeLike
Reblogged this on Bits n Bytes and commented:
A very simple and to the point introduction to Word Embedding by Abhay Padda.
LikeLiked by 1 person
Thanks UD for reblogging this! 🙂
LikeLike